This is the Ada/PM Reference Manual. Other available Ada/PM publications include:
A programming language reference manual is a form of documentation that is associated with a programming language. It is ordinarily separate and distinct from a programming language specification, which is usually more detailed and intended for use by implementors of the language itself, rather than those who simply want to use the language to create an application.
The Ada/PM Reference Manual is the authoritative source and rationale for the programming language. It defines the proper behavior of programs written in the language. Having this single reference provides several advantages. First, it is precise, and requires no interpretation. Disputes as to the meaning of a program can be settled simply by executing the program as specified in the reference manual.
Second, the reference defines the programming language so that users and implementors can agree on what programs in the language mean. It is written appart from any reference to a compiler or computer system.
Finally, the language's creators write it. This gives the implementation of the language its authenticity.
The overarching design goals of the Ada/PM programming language include the following imperatives:

Exploit the x86-64 Microprocessor
This publication is a comprehensive reference to the Ada/PM programming language. Ada/PM is a special-purpose programming language developed as an experiment in overcoming the immense size and verbosity inherent in currently available languages. As a practical software tool, Ada/PM integrates assembly language instructions with high-level source code to provide a readable, extensible, and safe programming language. Excerpts in the accompanying paragraphs are taken from the book, Ada/PM Reference Manual, First Edition.
NOTE Ada/PM Reference Manual and accompanying files are currently undergoing editing and testing. Thank you for your patience.
Good programming languages are concise. This means they include only the fundamental constructs to make programs work. To expand the functionality of the language, extensive component libraries should be provided. Useful libraries should (1) include text, numeric, and file input/output functions; (2) contain extensive math and text manipulation functions; (3) be reliable and efficient; (4) come with great documentation, and (5) be simple to implement.
An outstanding programming language gives users what they want; a language they will love. It is just as easy to design a good language as it is a bad one. The fundamental language itself should be concise but include adequate library functions to expand its power. The manual should be short as well. A well-designed language does not need lengthy clarifications, numerous warnings, or lots of special case examples.
This section provides an overview of the basic syntax used by Ada/PM. It provides a sense of the features expressed in the Ada/PM programming language with enough perspective necessary to understand the details.
One hallmark of a cogent programming language is its user's manual. The Ada/PM Reference Manual is designed as a reference document for the Ada/PM programming language. This straightforward resource covers the many detailed syntactical aspects of the Ada/PM programming language. In addition to being a reference, it incorporates example programs accompanied by programming tips, and recommended practices that demonstrate Ada/PM's range of features.
See Janus/Ada 1.1
Ada/PM is a special-purpose language designed to make x86-64 inline assembly language code an integral component of Windows-based programming. It is an imperative, statically typed language using block structures to group declarations and statements in separate parts of a program. Ada/PM focuses on low-level programming capabilities to extract the power of modern multi-core processors by manipulating data based on the inexorable Von Neumann computer architecture.
Ada/PM implements many of the syntactical features found in Ada 2012 and restrictions associated with SPARK 2014. Time-proven concepts are also borrowed from languages such as Pascal, Modula-3, and Oberon. The name stands for Ada Pascal and Modula. The aim is to exploit the strengths of these languages and avoid most of their verbosity and potential ambiguities. This is accomplished by implementing a strong static type system and making Ada/PM's syntax as orthogonal as is reasonable. This aids in making code more readable and making compiler design less complex.
Designed to be a highly readable language, Ada/PM employs a subset of optimized constructs and data types from several fifth-generation languages without sacrificing core expressiveness. Most of Ada/PM's expressiveness comes from its support libraries so that the basic syntax remains small. Ada/PM is a monolithic, single executable form of programming intended to reduce the design complexities of compiler construction and enhance user efficiency.
NOTE Being able to read and understand a program is far more important than how easy it is to write.
As with any imperative programming language, Ada/PM stores program instructions, declares typed objects, elaborates and stores objects as data, and then manipulates data using type-specific operations. Ada/PM operations are further strengthened using packages that separate interface specifications (headers) from implementation.
Ada/PM's structure offers two levels of program development. At the high level, Ada/PM's syntax is specifically designed to free users from the intricate details of the underlying system architecture. At the low level, Ada/PM provides extensive features explicitly designed to allow direct access to system hardware and external libraries using native assembly language instructions.
Most importantly, Ada/PM is primary focused on producing correct, error-free code containing no user surprises. To this end, Ada/PM relies on ample quantities of memory space for key language structures to ensure accuracy, contextual language compliance, and program safety.
See Janus/Ada 1.2
Chapters in the Ada/PM Reference Manual are generally numbered to match the 2012 version of the Ada Reference Manual (ARM). Some chapters and sections may be omitted or added due to the unique nature of the Ada/PM programming language.
See Janus/Ada 1.3
The main goal of Ada/PM is to facilitate assembly language programming. Understanding assembly language is a daunting challenge at best. However, the reason for learning assembly language is to be able to directly manipulate hardware devices, access specialized processor instructions, address critical performance issues, generate assembly code instructions in designing compilers, and most importantly, get a leg up on the competition by learning how high-level languages really work under the hood.
One approach to simplifying the task of learning assembly language is to allow assembly language instructions to be written right in the source code of an Ada/PM program. In a time when most high-level programming languages are distancing themselves from assembly language, facilitating inline assembly instructions requires a fresh 64-bit programming language based on simple syntactical constructs that natively supports assembly language mnemonics.
Corollary design considerations:
NOTE Ada/PM is focused on implementing inline assembly code, not being a large, all-inclusive general-purpose language.
The following list highlights some of the principle features of the Ada/PM programming language:
Subprograms group related data and statements that provide separate namespaces to prevent name collisions from occurring. They also encapsulate certain information details to simplify reading and writing programs.
Any text editor, such as Windows Notepad or the free Scintilla-based Notepad++, may be used to prepare an Ada/PM program. The program text must be a text file containing no formatting. The following program demonstrates how to compile a program from the command prompt:
C:\Users\AdaPM> Adapm name.ada -build
The "adapm" command is used to run the compiler. Next is the name of the file to compile. This is followed by the build switch. Switches have a dash (-) prefixed to the directive name. There are two directives: -build, which tells the compiler to build the entire program into an executable file with an ".exe" extension or -compile, which tells the compiler to merely compile the file into an object file with an ".obj" extension. Object files are used by the linker to include files into other programs.
1 ------------------------------------------- 2 -- High-Level Program: Greetings.ada 3 -- Last updated: June 20, 2020 4 ------------------------------------------- 5 with io; 6 package Greetings() is 7 const str : string = "Hello, world."; 8 9 begin 10 asm 11 lea rcx, [str] 12 call put 13 ret 14 end asm; 15 end Greetings; 16 -------------------------------------------
This file must be named "greetings.ada". The normal default file naming convention for Ada/PM requires that each file contain a single compilation unit whose file name is the subprogram name. The extension ".ada" is used for the package body or main subprogram of a program. Included library packages have the extension ".inc" to indicate the file is a subprogram interface like header files in languages like C/C++. Most of the facilities in Ada/PM are provided by library packages rather than being built into the structure of the language itself.
As shown in the next example, subprogram definitions have two parts, a declarative part, which is contained between the reserved words is and begin, and the executable part, which is contained between the reserved words begin and end. Following the reserved word end is a repeat of the package name and a semicolon. Repeating the subroutine name is optional, but the semicolon is mandatory.
-------------------------------
-- Basic Program Structure.
-- Shows the two parts of
-- every subprogram.
-------------------------------
package identifier is
-- declarations go here
begin
-- statements go here
end identifier;
-------------------------------
Notice that Ada/PM programming is free form. That is, you may add spaces and blank lines anywhere you wish to make the program more readable, provided of course that you do not split up an identifier or unary operator. Semicolons are used to terminate statements.
See Janus/Ada 1.6
Ada/PM programs are built out of declarations, statements, expressions, and comments, which consist of sequences of identifiers, symbols, and keywords. Notice that Ada/PM formats each line like the formatting found in most natural languages such as English. Semicolons terminate statements. Colons are used to separate identifiers from their type definitions. Colons and semicolons are typically placed right after the clauses they offset with no space in between, just as in natural languages. This manual uses different styles from time to time to demonstrate how they can be written.
White space such as tabs, spaces, and blank lines are used to improve readability. Note that spaces are required between identifiers, keywords, symbols, and number series. Spaces may be included within strings but are not allowed within identifiers and keywords.
NOTE - Except for inline assembly language instructions and blank lines, every new line in Ada/PM begins with an identifier or comment.
One objective of Ada/PM is to reuse existing pieces of programs so that new coding is kept to a minimum. This is where the concept of library units comes in. A complete Ada/PM program is intended as a main subprogram (itself a library unit), which calls upon other library units to provide additional services.
The main subprogram takes the form of a procedure of an appropriate name and support libraries can be subprograms (procedures or functions), but most likely are packages. A package is a group of related data and instructions including subprograms but may contain other entities as well.
1 ------------------------------------------------- 2 -- Demonstrate how to incorporate support 3 -- libraries into a program. 4 -- Updated: June 20, 2019 5 ------------------------------------------------ 6 with io, math; -- Library packages 7 package Put_Log is 8 use io; -- Declarations 9 var x : float; 10 begin 11 get(x); -- Statements 12 put(math.log(x)); 13 new_line; 14 end Put_Log; 15 ------------------------------------------------
The previous program is written as a procedure called "Put_Log" preceded by a with clause giving the names of the library units to be used in the program. Note that declarations are inserted between is and begin. Generally, declarations introduce the variables, constants, and types to be manipulated by the program. All statements are contained between the reserved words begin and end. Statements represent the sequential actions to be performed.
Writing use io; gives the program immediate access to the operations in the package io.h. Since there was no use clause associated with the math package, the program included the fully qualified name of the function, which included the name of the library unit followed by a period then the name of the function (i.e., math.log). Avoiding the use clause forces the program to include fully qualified names. In the previous example, the use clause is localized to the procedure and nowhere else because its scope was contained within the procedure. The use clause should be avoided or at least minimized. If used, localize its effects. Incorporate the use clause only in the following situations:
The following Listing shows Ada/PM's approach to low-level programming features. These features provide access to the underlying system hardware and to external library functions.
1 ------------------------------------------------------------------- 2 -- Demonstrate how to incorporate inline assembly language code 3 -- into a program. 3 -- Outputs "Hello, World!" to stdout 4 ------------------------------------------------------------------- 5 package Hello is 6 begin 7 asm 8 section .data 9 str db "Hello, world!", 10, 13, 0 10 11 section .text 12 extern _printf ; Make external library function visible 13 text_io: ; Label denotes start of procedure 14 mov rcx, str ; Address of str 15 call _printf ; Execute library print routine 16 ret ; Return to caller 17 end asm; 18 end Hello; 19 -------------------------------------------------------------------
The previous Listing shows an example of how assembly language instructions are employed in Ada/PM source code. Note that comments in assembly blocks start with semicolons (;). All assembly code is passed unchanged to the NASM assembler where assembly block comments are stripped out. Inline assembly language programming is the subject of another publication titled: Ada/PM Inline Assembly Language Programming. Therefore, inline assembly techniques will not be discussed here.
Nam qui facit per alium facit per se. With Great Power there must also come Great Responsibility. Harvard Law Review, Vol VII. No. 7, February 25, 1894, Blackstone, House of Commons, cf.; Amazing Fantasy #15, Marvel Comics, final panel, Peter Parker a.k.a. Spiderman; Winston Churchill, Franklin D Roosevelt, Luke 12:48, et al. Using assembly language gives you the ultimate power over the microprocessor; however, with this power, judicious care must be exercised because assembly language code is unchecked by the compiler--you are on your own.Page Top
The syntax of Ada/PM is described using a modified version of Backus-Naur Form commonly called BNF. Details concerning Ada/PM's syntax is covered in the Ada/PM Compiler Design and Development manual. We will use BNF syntax in discussing Ada/PM's lexical elements.
Ada/PM programs are written as a sequence of lines composed of strings of text characters that form lexical elements called lexemes. The only characters allowed in Ada/PM programs are those corresponding to the basic ASCII character set, which comprises the 128 seven-bit ASCII characters. All Ada/PM programs can be written using this basic character set.
ASCII characters 0 to 31 and character 127 are non-printing and mostly obsolete control characters. except for string and character literals, upper- and lower-case characters are considered the same in Ada/PM programs.
Printable ASCII Characters
upper case letters ::= A .. Z
lower case letters ::= a .. z
digits ::= 0 1 2 3 4 5 6 7 8 9
special characters ::= ~ ` ! @ # $ % ^ & * ( ) - _ + = { } [ ] | \ : ; " ' < > , . ? /
space characters ::= space tab blank_line
Single-character symbols are composed of a single character. Single-character symbols with their names are shown in the next figure.
Single-Character Symbols
Symbol Name Symbol Name Symbol Name
~ tilde ) rparen : colon
` grave, backquote _ underscore ; semicolon
! exclamation - hyphen, minus " quote, double_quote
@ at_sign + plus, addition ' apostrophe, single_quote
# hash = equal, assignment < langle, less_than
$ dollar { lbrace > rangle, greater_than
% percent, modulus, remainder } rbrace , comma
^ circumflex, indirection [ lbracket . period, decimal, dot
& ampersand, address of ] rbracket ? question, variadic
* asterisk, multiply × | bar / slash, divide ÷
( lparen \ backslash
The next figure shows how single-character symbols are used.
Using Single-Character Symbols
x, y, z : float = 0.0; -- Commas separate expressions
pi : float = 3.14; -- Colons separate identifiers from type-definitions
put (12345); newline; -- Semi-colons separate multiple statements
MyChr : char = 'A'; -- Single quotes contain character types
type BigArray is array [10] of float; -- Brackets contain array indices
type WeekEnd is {Sat, Sun}; -- Braces contain aggregate identifiers
procedure AddNum (x : integer) is -- Parentheses contain subprogram parameters
index = rate / 100; -- Whitespace separates symbols
Compound symbols are composed of two adjacent special characters. A list of Ada/PM's compound symbols are shown in the next figure along with their names.
Compound Symbols Symbol Name Symbol Name => choose, goes to <= less_than_or_equal ≤ .. range >= greater_than_or_equal ≥ \x escape sequence ** exponent != not_equal_to ≠ <> box, dynamic array size := reserved /* start block comment -- single-line comment */ end block comment += compound addition *= compound multiplication -= compound subtraction /= compound division %= compound modulus -> arrow, reserved
The next figure shows how compound symbols may be used.
Using Compound Symbols if x >= y then -- Greater_than_or_equal ≥ while index != false do -- Not_equal_to ≠ procedure Area (x => length, y => width) -- Goes to => type index is range 1..100; -- Range .. x : integer = 15; -- Assignment x *= 15; -- Compound multiply (i.e., x = x * 15)
Ada/PM's syntax rules specify which lexemes are part of the language. Ada/PM's lexemes include: (1) user-defined identifiers, (2) special words, (3) literals, (4) white space, (5) special characters, and (6) comments.
An identifier is a name given to variables, constants, subprograms, packages, and classes. When declaring a user-defined identifier, identifiers must start with a letter and may be followed by zero or more upper- and lower-case letters, single underscores, and digits.
Punctuation characters such as %, @, $, and & are not allowed to be used as part of a name. An identifier name cannot start or end with an underscore nor can an underscore be the only character. Spaces must separate identifiers, cannot contain any spaces as part of their names, and cannot start with a digit. Stand-alone reserved words cannot be used as identifiers.
Examples of User-Defined Identifiers VALID IDENTIFIERS INVALID IDENTIFIERS Add_Two_Numbers Add__Two__Numbers -- Cannot use two adjacent underlines P25_Units 25_Units -- Cannot use a digit as the first character Return_Value RETURN -- Cannot use stand-alone reserved words My_3_Variables My#3&Variables: -- Cannot use symbols other than underscores x_1 _ -- Cannot use single stand-alone underscores myArray _myArray -- Cannot use an underscore as first character Big_Definition Big_Definition_ -- Cannot use an underscore as last character A315_Vectors A315 Vectors -- Cannot use spaces within a name package_1 package -- Cannot use a reserved word
Once declared, an identifier name may be prefixed with a unary operator (+ | - | ^ | & | $); infixed with memory addressing operators (. | `); or post fixed with terminating, separating, and bracket delimiters. Prefix operators and infix operators must be kept adjacent to their identifier names while postfix delimiters can have spaces before or after their symbols as shown in the next figure.
Ada/PM identifiers, including reserved words and keywords, are case-insensitive. This means named objects may contain a mix of upper- and lower-case characters. Names differing only in upper- and lower-case letters, in corresponding positions, are considered identical. That is, Ada/PM treats MyString the same as mystring.
A literal is a syntax format for representing a fixed value in source code. When defined, literals become constant values (immutable) of the type being represented and cannot be redefined during program execution. All literals are stored in read-only memory and cannot be accessed. Since literals have no names associated with them, they are considered anonymous objects and without associated names, they cannot be accessed. Ada/PM defines four literal types: (1) numeric, (2) Boolean, (3) character, and (4) string.
Ada/PM uses two classes of numeric literals to represent numbers. They are (1) discrete and (2) real. All numeric literals begin with a digit or alternatively with a plus or minus sign followed by one or more digits. Isolated commas may be inserted between adjacent digits to facilitate ease of reading. Real literals include a decimal point while integers do not. Numeric literals cannot contain symbols or spaces other than decimals, commas, and exponential notations.
Numeric literals may contain an exponent indicating a power of ten by which the value of the literal is to be multiplied to obtain a value without the exponent. Base 10 exponents are denoted by the use of either the "e" or "E" character followed by the integer value of the exponent. Regular exponents are denoted using the carat ^ symbol. Note that integer values cannot contain a negative exponent because that would infer a floating-point number. The exponent part of a numeric literal cannot contain any commas. The following numeric literals are permitted by Ada/PM:
Numeric Literal Examples -15 -- Negative integer type 123e5 -- Integer value with base 10 exponent of 5 10525697134 -- Integer value 1.923756E+305 -- Floating-point type 125505.99 -- Decimal type 4**2 -- Integer value to the base 10 power of 2 5.0 + 0.0j -- Complex number expression
Ada/PM requires commas to be used as separators in numeric literal lists to enhance readability. For this reason, white space must separate a series of individual numbers. The current version of Ada/PM does not support the use of underscores in numbers.
String with Commas versus List of Numbers
var str : string = "123,456,789"; -- String containing a nine-digit number
var a : array [3] of integer = {123, 456, 789}; -- List of three separate numbers
The values FALSE and TRUE are also treated as literals in Ada/PM programs. Examples of Boolean literals are shown in the following example.
Declaring Boolean Literals var finished : bool = true; -- Assign true to finished var on_off : bool = false; -- Assign false to on_off
Character literals are formed by enclosing a character within single quotes ('). Examples of character literals are shown in the next example.
Declaring Character Literals var c: char = 'A'; -- ASCII character A var c: char = ' '; -- ASCII space character var c: char = '&'; -- ASCII ampersand &
Strings represent arrays of printable characters including spaces enclosed in double quotes " ". They may also contain just one character or may be null. All Ada/PM strings must fit onto a single line. Concatenation, denoted by the + symbol, is used to represent strings longer than one line.
Figure 15. String Literal Examples "A typical string enclosed in double quotes." -- Typical string format "This is a very big and very long string that" + -- String catenation " demonstrates how to combine two lines of strings." " " -- Space "" -- Null string "A quoted phrase \"index\" and a newline \n" -- Embedded escape sequences
Ada/PM allows control characters to be embedded in formatted strings using escape sequences. Escape sequences begin with the backslash \ symbol.
Figure 16. Ada/PM's Escape Sequences Sequence Meaning Sequence Meaning \b Backspace \\ Backslash \f Form feed \' Single quote \n Newline \" Double quote \r Carriage return \0 String terminator \t Horizontal tab \xnn Hex value nn
The reserved word pragma indicates the start of a pragma. Pragmas are instructions used to convey information to the compiler. Pragma is short for pragmatic information. The pragma reserved word is followed by an identifier (i.e., the name of the pragma), and optional parameters enclosed in parentheses. The standard syntax for an Ada/PM pragma is:
pragma identifier [(parameter {, parameter})];
where the parameter list is optional. Pragma directives are not part of Ada/PM's grammar and as such, do not invoke a lot of reserved words in which to contend. There are three kinds of pragmas. Global pragmas that affect behavior over the entire program. Local pragmas that only affect local sections of a program such as a block of programming code. Optional hints that may be ignored by the compiler. Pragmas do not perform any action in the program itself, they merely change the behavior of the compiler.
Pragmas are only allowed in the following places in a program:
Unrecognized pragmas will raise an error if warning is set to on. Figure 17 depicts some of Ada/PM's pragmas.
Figure 17. List of Pragmas stringsize (160) -- Set default size of string variables to 160 bytes precision (4) -- Set real value precision warning (on/off) -- Turn unrecognized pragma error warning on/off optimize (on/off) -- Turn compiler optimization on/off comment (on/off) -- Turn block commenting on/off
Single-line comments begin with two hyphens -- followed by zero or more characters. Single-line comments end at the end of line and cannot extend over multiple lines. Block comments are enclosed using the slash/asterisk combination /* */. These symbols allow multiple lines of code to be commented out during testing and debugging.
My preference is to not use double slashes to begin comments or the slash/asterisk combinations, but they are ubiquitous in many programming languages. They are also prevalent in many support tools such as Notepad++, Help & Manual, and HelpSmith where C-style comments can be set as the default.
For safety reasons, using two characters to start comments does make sense. Double characters avoid starting a comment by accident, which could occur if a semicolon (;), hash (#), apostrophe ('), or exclamation (!) were used. Additionally, the use of two hyphens --, as used in Ada syntax, is ambiguous as are parentheses (), used by Pascal and Forth, or braces {}, used by Haskell. To avoid ambiguity, the decrement -- and increment ++ prefix/postfix symbols are not used by Ada/PM. This also simplifies compiler design.
-------------------------------- Comment forming a line -- Line containing a standalone comment var index : integer = 100; -- Comment following a statement -- const pi : float = 3.14159; is a comment and not a declaration /* Block comment, enclosed in a set of pragmas can be extend over multiple lines. */
Ada/PM reserved words are terms that have special meaning and cannot be used for any other purpose. That is, reserved words cannot be used by programmers for user-defined identifiers, names of variables and constants, names of packages, names of subprograms, and names of labels. Reserved words are necessary to make parsing unambiguous and to improve program readability.
Ada/PM distinguishes between reserved words and key words. Whereas reserved words can never be used for other purposes, key words may be used unless a library package is imported that contains specific key words. It is generally best not to use key words for user-defined identifiers.
| access | all | and | any | array | asm | begin | body | case | const |
| delta | digits | else | elsif | end | exception | exit | for | free | function |
| goto | if | is | loop | new | not | null | of | or | others |
| package | private | procedure | range | record | return | reverse | subtype | then | type |
| type | use | var | when | with |
NOTE Additional reserved words may be added as the language matures. Obsolete and unused reserved words may be eliminated.
White Space consists of spaces, horizontal tabs, vertical tabs, blank lines, and end of line (EOL) markers. The compiler is insensitive to white space and except for spaces contained in quoted strings, generally ignores white space. White space is used to improve program readability and delineate identifiers and symbols.
index : integer; -- White space between colon and expressions
index: integer; -- Same as above; note colon position
put (100) ; new_line; -- White space between semi-colon and expressions
put(100); new_line; -- Same as above; note semi-colon position
BigArray [100]; -- White space between identifier and bracket symbol
BigArray[100]; -- Same as above; note bracket position adjacent to identifier
-- Blank lines are ignored by the compiler
put ("Hello world!"); -- White space in quoted strings are meaningful
x = index + rate; -- Tabs that begin new lines are ignored by the compiler
a = b * c; -- Note white space around the assignment and multiplication signs
NOTE - Ada/PM allows semi-colons, colons, parentheses, and brackets to be placed next to the left-hand clause. This is perfectly acceptable and is allowed so that programmers used to coding in this style can do so without causing exceptions.Page Top
See Janus/Ada 3, ARM 3
Ada/PM's type system is a collection of rules for checking the consistency of its programs. That is, a set of values, together with associated operations on those values. It turns out that type systems require the development of precise notations and definitions of types for stored objects and accompanying rules on allowed ranges of values and how various types can interact with each other.
For instance, a signed integer on a 64-bit system can assume whole number values in the range of -263 to +263-1. Ada/PM's type system prevents signed integers from being added to strings, or any other non-compatible type. Signed integer types can be compared, added, subtracted, multiplied, and divided from one another, but not other types such as reals or Boolean values.
Ada/PM is a strongly typed language by virtual of its type system that requires explicit type syntax. An Ada/PM object must be given a type before it can be used. The variable may be used only in operations appropriate for the type and may contain only values of the designated type. Types are incompatible with one another, so it is not possible to mix two different types. There are; however, ways to convert between types. Types are statically checked during the compilation process. This allows type errors to be found early.
The primary goal of a type system is to ensure language safety by ruling out all untrapped errors in all program runs. However, most type systems are designed to ensure the more general good behavior property, and implicitly safety. Thus, the declared goal of a type system is usually to ensure good behavior of all programs, by distinguishing between well typed and ill typed programs. Luca Cardelli, Microsoft Research
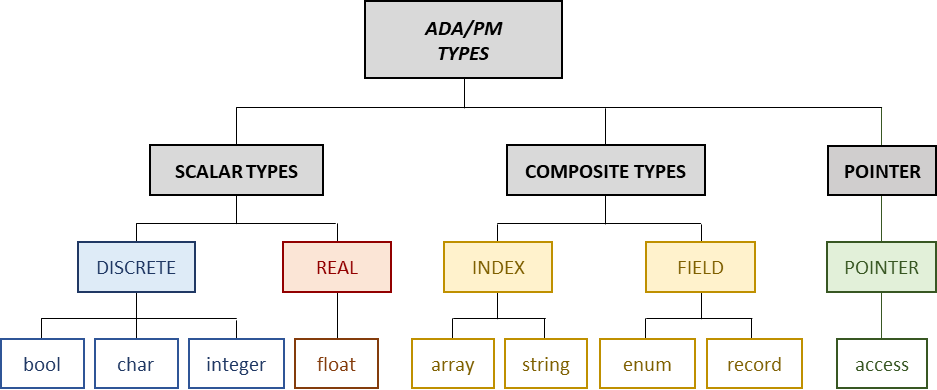
As illustrated in the next two figures, Ada/PM contains four scalar types: bool, char, integer, and float; four composite types: array, string, enum, and record; and a pointer type: access. Scalar types are predefined universal types included in the standard package. In Ada/PM, an object is something that can contain a value and is stored in memory. All objects are either constants or variables.
See Janus/Ada 3.2, ARM 3.3
The data that takes up actual storage locations in memory are called objects. Every object has a name called an identifier that references its computer memory address. Every object has an associated type that determines the range of values the object can store in memory and the set of operations explicitly defined for values of that type. Every object has a related storage class that establishes its lifetime. Finally, every object has a scope defined by where in the program the object is declared and depending on its storage class.
The rules governing Ada/PM's type system specify that every object:
Ada/PM provides two fundamental kinds of objects: variables and constants. Objects are created (elaborated) by means of declarations. When declared, objects are assigned a memory location of a specific size based on its type. Objects are initialized with a value constrained by its range of allowable values. Variable objects may be assigned different values at different times during program execution. The values of constant objects are set when defined and cannot be changed during program execution.
Variables and constants both store data. The difference between them is that the data stored in a variable can be changed during program execution, whereas the data stored in a constant cannot. Both must be declared as a specific type, but only the constant requires a value (the data) to be assigned (initialized) when it is declared.
In Ada/PM, variables and constants are called objects. This has nothing to do with object-oriented programming. A variable in Ada/PM is an object that has been declared as a given type and with an optional explicit value. A constant is the same, except the declaration now contains the reserved word constant and the initial value is no longer optional but required.
Both variables and constants are declared in the declarative part of a subprogram. More can be read about the structure of Ada/PM programs later in this document.
Note that Ada/PM objects must be declared, elaborated, and initialized before they can be used. Variable and constant declarations must be declared in the declaration section of a subprogram or package.
Ada/PM data types define the format and size of data stored in computer memory and are characterized by a set of values and a set of operations. This allows programmers to create powerful abstractions that represent real world problems. Ada/PM provides a standard syntax for defining types and associating them with objects. Strict type checking is implemented to ensure prohibited language implementations of data types are reported as early as possible.
Ada/PM's data type system adheres to the following contextual rules:
Ada/PM implements two kinds of data types: (1) predefined and (2) user-defined. Predefined types represent a set of primary data types that are built into the Ada/PM programming language. They are reflective of the hardware architecture and include scalar and text types. The benefit of predefined data types is that they do not need to be explicitly declared before they are elaborated and used in a program. Predefined types are defined in Ada/PM's standard library package.
User-defined types represent more complex data types that are built up from predefined data types. They must be explicitly declared before they can be elaborated and used in a program. User-defined types include composite, structure, and reference types.
Variables represent abstractions of computer memory. Values consistent with the variable's type may be assigned to the variable in the body of a program. New values assigned to variables simply replace whatever value was previously assigned. A variable is declared like this:
var identifier : type [= value];
Creating variables is also called declaring variables. identifier is a name associated with the object and links it to the memory location of the stored value. A variable name can hold a single type of value. type defines the type that the variable will be bound to during program execution. value represents an initial value assigned to the object. Assigning a value to an object is optional. Just note that Ada/PM implicitly initializes objects with default values if the user assigned none. Except for anonymous types, variables are required to be declared and initialized (defined) before they can be used. Failure to do so raises an error. Here are examples of variable object declarations.
var x : integer = 500; -- Declare single initialized variable var x, y, z : float; -- Declare multiple uninitialized variables
Variables come into existence only when the program reaches the line of code where they are declared. Depending on their type, appropriate storage space is set aside in memory. Variables go out of existence when the program leaves the scope of the variable; i.e., they are no longer accessible to a program unit. Variables become initialized when values are explicitly or implicitly assigned.
The reserved word var is used to declare a variable. It tells the compiler to set the scope of the variable and to include its type and associated operations when the object is created in memory. Inside a subprogram, all undeclared variables are global and must have been pre-declared before they can be used. Only those declared with var inside the subprogram are local. This becomes very important when you have a lot of subprograms. We need var at top-level because every top level statement starts with a keyword, thus maintaining orthogonality.
Note that Ada/PM implicitly initializes declared variables to zero if not explicitly initialized by the user. Some experts suggest that automatically initializing variables often results in the unintentional use of invalid values in computations. However, Ada/PM prefers to initialize undefined variables in order to allocate storage space and prevent the use of indeterminate values. A check that the variable has been set to zero makes it easy to determine if it has been initialized or not by the user.
Ada/PM employs four storage classes: (1) stack, (2) heap, (3) register, and (4) static. Variables declared within subprograms are usually stored on the stack. These are considered local variables that exist only during subprogram execution. Variables declared dynamically such as pointers, trees, dictionaries, temporary strings, etc., are generally placed on the heap. The heap is a managed section of memory used to store dynamic objects. Heap variables only exist if the structures such as procedures and functions that define them exist. Variables used for such things as indexes and counters are typically placed in a CPU register. Register variables exist only if the flow structures such as loops execute. Static variables persist throughout the lifetime of the program. They are generally stored in permanent memory.
The reserved word constant declares the object to be a constant. A constant is an immutable object having an assigned value that cannot be changed during program execution. Constant declarations look just like variable declarations except that the reserved word constant is used in the declaration. Objects declared as constants must be initialized with a static expression whose value is known at compile time.
Constants are an important tool to help make programs more reliable and maintainable. A constant is, just like a variable, a reference to a specific type of data, but where they differ from variables is in their static nature. Variables are mutable (changeable), constants are immutable (unchangeable). When declared and initialized, the data constants reference is no longer alterable. If you try to alter a constant, the compiler will complain. The syntax of a constant declaration is:
constant identifier : type = static_expression
The reserved word constant declares the object to be a constant. identifier is a name that refers to the memory location of the stored data object. type defines the type that the constant represents. static_expression represents a mandatory assignment of a value. Examples of constant object declarations are shown in Figure 23.
Figure 23. The Constant Reserved Word const index : integer = 500; -- Constant object of type integer const pi : float = 3.1416; -- Constant object of type float const prompt : string = "Type a number: "; -- Constant object of type string const P : integer = -15; -- Constant object using a static expression const CR : char = '\n'; -- Constant object of type char
Note that it makes sense that constants can represent only predefined scalar and string types such as integer, float, string, and char. All constants are immutable. This means all Ada/PM constant expressions must evaluate to a static value during compilation. During program execution, they become read-only. A constant expression cannot contain the name of a variable, a function call other than a call of a predefined operator or attribute, an indexed component, or a composite data type.
Note that all constants have a static storage class and persist throughout the lifetime of the program. An error will be reported for any constant that is not assigned a static value when declared. An error will also result if an attempt is made to alter the value of a constant during program execution. Ada/PM treats constant declarations like preprocessor commands such as #define used by other languages.
The operations that can be performed on different kinds of objects depends on their type definition. Scalar data types can be used with the relational operators ==, !=, <, <=, >, and >= and the arithmetic operators +, -, *, /, and ^. Discrete types can be used with the additional arithmetic operators % and REM. The following figure shows how Ada/PM employs operators.
Figure 24. Operators in Use z = 250 -- Assignment operator a + b -- Plus arithmetic operator x != y -- Not_equal_to relational operator m**n -- Exponent operator x % y -- Integer modulo operator
Attributes are predefined characteristics of named types and objects. Some attributes are functions and play an important role in the manipulation of scalar and discrete data types. Attributes are formed by appending an attribute designator to the object separated by a grave symbol (`). The grave symbol is used so as not to overload other symbols such as the quote ('), dot (.), or colon (:) and to make attribute definitions look different from dot notation. There are several built-in attributes defined in Ada/PM, Figure 25 lists some examples.
Figure 25. Built-In Attributes name`first -- Yields the value of the lower bound of a named identifier name`last -- Yields the value of the upper bound of a named identifier name`length -- Yields the length of a string not including the terminator name`size -- Yields the size in bytes of an object's reserved memory space name`pos -- Yields the position of an enumeration identifier in a list name`address -- Yields the address of the named identifier name`value -- Yields the value of a named identifier name`pred -- Yields the identifier preceding the named identifier name`succ -- Yields the identifier succeeding the named identifier
See Janus/Ada 3.1, ARM 3.1
Every built-in type defined by Ada/PM syntax is considered to be declared in the package standard, which is automatically imported into every Ada/PM program. In Ada/PM, every type declaration introduces a new type, which is distinct from every other type. The set of values belonging to two distinct types are also distinct from each other. By design, values of different types cannot be assigned to each other. Ada/PM's strong typing ensures that assignment of incompatible types raises an error.
Ada/PM provides two built-in types: primary and composite. Primary types include bool, char, enum, integer, natural, float, decimal, and pointer. Composite types include array, map, record, and string. Ada/PM's type declaration syntax takes the form:
type identifier is type-definition;
Ada/PM uses a different format for declaring types than it uses for declaring objects. This is to emphasize the conceptual difference between the two declarations. Objects exist in memory whereas type declaration information is placed in the symbol table, not in memory as an object. The reserved word type is followed by the identifier name to be associated with the type, the reserved word is, and then the type_definition. Figure 26 shows some examples of type declarations.
Figure 26. Type Declarations
type aircraft is {Beechcraft, Cessna, Cirrus, Mooney, Piper};
type count is integer range 1 .. 100;
type sales is array [count] of aircraft;
Notice that the information in curly braces { } after the reserved word is defines the five literal values belonging to enumerated aircraft type. The second declaration introduces a completely new integer type, which contains 100 values belonging to the type count. As discussed previously, type declarations are only templates and do not take up any memory. Objects of both types can be declared in the following way:
A : aircraft; -- Declare object A as type aircraft C : count; -- Declare object C as type count
Since both declarations introduce completely different types, values of one type cannot be assigned to variables of another type. Therefore, they cannot be mixed. Figure 27 demonstrates this rule.
Figure 27. Types Cannot be Mixed var I : integer -= 15; var A, B : aircraft -= Cessna; var C : count -= 99; -- Invalid assignment of incompatible types I = C; C = A; A = I; -- Valid assignment of compatible types I = 1000; A = Cessna; B = A; -- A and B both have values of Cessna C = count`last; -- Assigns 100 to C
Ada/PM will report an error when it detects any attempt at assigning incompatible types during compilation. Strong typing used in the manner shown in the last example is designed to ensure that only similar types can be mixed in order to avoid incorrect programs.
See ARM 3.2.2
Ada/PM uses the reserved word subtype to represent subsets of values of base types. Although a subtype can represent a complete set of a base type, they are normally used to form constraints of base types. Constraints are required and take various forms according to the category of the base type. Although subtypes can constrain the range of base type values, they cannot restrict the set of operations of base types. Subtypes assumes all the operations allowed by base types because subtyping only applies to the values of the base type. The following syntax shows how subtypes are declared:
subtype identifier is type-definition;
For instance, the following example employs a subtype declaration of a base type.
type Planets is enum {Mercury, Venus, earth, Mars,
Jupiter, Saturn, Uranus, Neptune}; -- Base type
subtype Gas_Planet is Planets range Jupiter .. Saturn; -- Subtype with range constraints
G : Gas_Planet = Saturn; -- Elaboration of a subtype variable
The compiler will now ensure that only Jupiter or Saturn can be assigned to variable G. If, as an example, a program attempts to assign Venus to G, an error will be raised.
Note that subtype declarations do not introduce new distinct types. As depicted in the next Listing, an object such as X, which is of type integer, can be assigned a value of another type that is of type integer.
subtype days_of_the_year is integer range 1 .. 365; var D : days_of_the_year; var I : integer = 10; var J : integer = 500; D = I; -- Perfectly legal assignment D = J; -- Raises a constraint error, D only accepts values in the range 1..365
Ada/PM contains two classes of data: primary types consisting of discrete, real, and reference types; and composite types. These types are built-in as part of the language and need not be formally defined by the user.
Scalar types describe ordered values. Two predefined attributes, called first and last return the lowest and highest values respectively for real named objects. Ada/PM provides two kinds of real types: float and decimal.
Ada/PM's predefined float type is a subset of real numbers and is represented using floating-point notation. All Ada/PM floating-point types must contain a decimal point, at least one digit to the left and at least one digit to the right of the decimal, and an optional exponential integer value denoted with an exponent symbol "e" or "E". The purpose of floating-point types is to extend the range of values that can be represented in computations.
Floats are stored using 64-bits where bits 0 through 51 contain the significand value, bits 52 through 62 hold the exponent, and bit 63 contains the sign value where 0 denotes a positive value and 1 denotes a negative value. As a result, type float has 53 bits of precision expressed in 16 digits of accuracy. The definition of the predefined type float is shown here:
type float is range float`first to float`last;
where: float`first = ±2.225073858507201e-308
float`last = ±1.797693134862316e+308
Examples of float declaration and elaboration are shown here:
Figure 29. Float Declaration and Elaboration type flt is float; -- Float declaration var width : flt = 1.123e45; -- Initialized variable of type flt var length: flt; -- Uninitialized variable of type flt var height: float = 123456789e15; -- Anonymous float type
Note that variables width and length are of the same type. This means width = length is a legal assignment. Further, width = height is a perfectly valid assignment because variables width and height are both of type float.
Floating-point values that underflow or overflow the allowable minimum and maximum values for float types will cause program execution to halt and an underflow/overflow error message to be reported. Likewise, any values that exceed user-defined range specifiers such as {-1.5 .. 1.5}, will cause program execution to halt and a bounds error to be reported. Finally, any attempt to divide by zero will result in program execution being halted and a divide by zero error message to be reported. However, underflow/overflow and divide_by_zero pragmas can be set so that instead of halting program execution, the compiler substitutes float`first or float`last when an underflow or overflow condition exists or cause a zero to be returned in the case of a divide by zero condition.
Ada/PM's predefined decimal type is a subset of real numbers and is represented using fixed-point notation. All Ada/PM decimal types must contain a decimal point, at least one digit to the left of the decimal, and exactly two digits to the right of the decimal. Decimal types do not contain exponents like the float type. The purpose of decimal types is to provide accurate financial calculations with no loss in decimal point accuracy.
Fixed-point types consist of two components: significand and fractional parts. The significand is stored as a 64-bit signed integer type where the most significant bit (bit 63) represents the sign of the number. This means that the significand part provides 63 bits of precision expressed in up to 19 digits of accuracy. The fractional part has a range of 0 to 99 and does not suffer from loss of accuracy due to rounding. The definition of the predefined decimal type is shown here:
type decimal is range decimal`first .. decimal`last;
where: decimal`first = -9,223,372,036,854,775,808.99
decimal`last = +9,223,372,036,854,775,807.99
Examples of a decimal type declaration and elaboration are shown here:
Figure 29. Decimal Declaration and Elaboration type dec is decimal range -100.00 to 125696781.25; -- Constrained decimal type var a : dec = 15.25; -- Initialized decimal variable of type dec var b : dec; -- Uninitialized decimal variable of type dec var big_decimal : decimal = 715884105727.18; -- Anonymous decimal type
Decimal values that underflow or overflow the allowable minimum and maximum values for decimal types will cause program execution to halt and an underflow/overflow error message to be reported. Likewise, any values that exceed user-defined range specifiers such as {-100.0 to 125676781.25}, will cause program execution to halt and a bounds error to be reported. Finally, any attempt to divide by zero will result in program execution being halted and a divide by zero error message to be reported. However, the underflow/overflow and divide_by_zero pragmas can be set so that instead of halting program execution, the compiler substitutes decimal`first or decimal`last when an underflow or overflow condition exists or return a zero in the case of a divide by zero condition.
In addition to being ordered, discrete data types provide a finite set of unique predecessor and successor identifiers. This gives discrete types an explicit first and last value in each set of identifiers. Each value other than the first has a unique predecessor, and each value other than the last has a unique successor. A value is greater than its predecessor and less than its successor. Identifier names in an enumerated list are called aggregates or aggregate elements. Ada/PM's discrete types include: bool, char, enum, integer, and natural.
Ada/PM provides two predefined enumerated types: bool and char. The predefined bool type can only have one of two possible values: FALSE or TRUE. Boolean 0 typically refers to logical false while true is always a non-zero value. The purpose of Boolean types is to represent flags that can be used to provide flow control within programs. Boolean types also enhance readability because they convey better meaning than do integer alternatives. Here is the definition of the predefined bool type:
type bool is enum {FALSE, TRUE}; -- Predefined enumeration type
where: bool`first = false
bool`last = true
Ada/PM's predefined CHAR type reflects the sequence of characters enumerated in the ASCII character set. Characters are enclosed in single quotes and are stored in memory as single bytes. The purpose of character types is to provide a flexible means of processing single character codes that can be converted to numeric values when needed. Here is the definition of the predefined char type:
type char is enum {char`first, char`last}; -- Predefined enumeration type
where: char`first = chr (0)
char`last = chr (127)
Examples of a char type declaration and elaboration are shown here:
Figure 30. Char Declaration and Elaboration
type vowel is char {'a', 'e', 'i', 'o', 'u'}; -- Constrained char type
var ch1: vowel = 'e'; -- Initialized variable
var ch2: vowel; -- Uninitialized variable
Ada/PM's enum type represents an ordered list of user-defined integer constants taking the form of literal identifiers or characters. The set of permissible values are known as enumerators. The order relationship among the literals of an enumeration type is fixed when the type is declared. The syntax for declaring enumerated types is:
type identifier is {identifier, ..., identifier}; -- Type declaration
type Color is {Red, White, Blue}; -- Variable declaration
The purpose of enumeration types is to provide a means for defining a type by listing identifiers for all the values in a defined set. This improves readability and reliability because identifier names are easily recognized. Basically, enumeration identifiers act like type-safe constants. The definition of the predefined enumeration type is shown here:
type identifier is {literal_1, .., literal_N};
where: identifier`first = literal_1 -- Value of left-most position in a list
identifier`last = literal_N -- Value of right-most position in a list
Positional lists of enumerated literals are called aggregates. Aggregates represent a collection of one or more identifiers or characters. Inclusive literals are enclosed in braces and separated by commas. The individual literals of an aggregate list are ordinal in that they are positional in nature. This means the left-most literal, in position 0, is lower in value than its successor values to the right. The right-most literal, in position n, has the highest value. A typical declaration of an enumerated type and elaborated variables are shown here:
Figure 31. Enum Declaration and Elaboration
type weekdays is {Mon, Tue, Wed, Thr, Fri}; -- Mon = 0, Tue = 1, Wed = 2, Thr = 3, Fri = 4
var today: weekdays = Mon; -- Initialized enum variable of type weekdays
var workday: weekdays; -- Uninitialized enum variable of type weekdays
workday = today; -- Legal assignment, both are of the same type
Note that enumerated identifiers are case insensitive, so that "mon" has the same meaning as "Mon". Literal names in any given list may not be repeated. Technically, there is no upper limit on the number of literals that can be included in a list, but there must be at least one. An empty enumeration type is not allowed. User-defined enumeration types typically contain only a small number of identifiers.
Ada/PM also allows the internal codes used to represent enumerated literals to be specified using aggregate assignments. Internal codes must be integer values declared in the same order as they appear in the aggregate list, and they must be in ascending order. Aggregate assignment is shown in the following example:
Figure 32. Enum Aggregates
type engine_hp is { -- Enumerated type with explicitly assigned values
model_10 = 100,
model_20 = 205,
model_30 = 308};
var hp: engine_hp = model_20; -- hp`value = model_20; hp`pos = 205
Ada/PM does not allow overloading of enumeration literals within the same scope. The following example shows that the literal Saturn is used in two different declarations in the same scope.
Figure 33. Overloaded Enum Names
type automobile is {Corvette, Impala, Saturn, Buick}
type planets is {Mercury, Venus, earth, Mars, Jupiter, Saturn, Uranus, Neptune}
var gas_planet : planets = Saturn -- Illegal declaration because Saturn is ambiguous
In order to use duplicate literal names like Saturn belonging to different types in the same scope, both must appear using fully qualified names as shown here:
gmc: automobile = automobile.Saturn; -- Fully qualified name gas_planet = planets.Saturn; -- Fully qualified name
Anonymous enum variables can be declared as shown here:
var color = {blue, green, red, yellow}; -- Anonymous enum type
Ada/PM's integer type represents a subset of whole numbers. Integers are 64-bit signed data types stored in twos complement format where the most significant bit (bit 63) represents the sign of the number. This allows Ada/PM integers to provide 63 bits of precision expressed in up to 19 digits of accuracy. Additionally, integer types can be used with the arithmetic operators +, -, *, /, %, and ^. The main purpose for integer types is to provide finite subscript indices in arrays, precise counters in iterative routines, clear-cut relational decisions in expressions, and accurate memory addressing and allocation. The definition of the predefined integer type is shown here.
type integer is range integer`first .. integer`last;
where: integer`first = -9,223,372,036,854,775,808
integer`last = +9,223,372,036,854,775,807
Examples of integer type declarations and elaboration are shown here:
Figure 34. Integer Declaration and Elaboration type int_nat is integer range 0 .. integer`last; -- Constrained integer type declaration var x: int_nat = 50; -- Initialized variable object var y: int_nat; -- Uninitialized variable object var nat: integer = 100; -- Anonymous variable declaration
Integer values that underflow or overflow the allowable minimum and maximum values for integer types will cause program execution to halt and an underflow/overflow error message to be reported. Likewise, any values that exceed user-defined range specifiers such as {1 to 10000}, will cause program execution to halt and a bounds error to be reported.
Any attempt to divide by zero will cause program execution to halt and a divide by zero error message to be reported. However, the underflow/overflow and divide_by_zero pragmas can be set so that instead of halting program execution, the compiler substitutes integer`first or integer`last when an underflow or overflow condition exists or return a zero in the case of a divide by zero condition. The purpose of these pragmas are to keep the program from halting during critical operations.
Note that the type declaration in the previous set of examples defines a constraint using the reserved word range. As shown, the declaration for int_nat defines it as type integer with values constrained to the range 0 .. integer`last. The next line elaborates a variable named "x" as an int_nat type, which means it is allocated 8 bytes of memory space and is assigned an initial value of 50. The compiler will verify that any assignment to variable "x" is in the specified range 0 .. integer`last. The variable y is of type int_nat too but has not been explicitly initialized. In this case, the compiler implicitly assigns it the value 0.
Finally, notice that "nat" represents an anonymous variable declaration. Anonymous types represent unnamed type variables. Unlike x and y, which are named variables of type int_nat, nat derives from the universal type integer and is compatible with any other integer whose parent type is of universal integer.
Ada/PM's unsigned integer type, denoted by the keyword natural, provides for cyclic computations. Although natural types represent unsigned integer types, they possess a special wrap-around property. That is, when a natural value reaches a maximum defined upper limit, the value wraps around to the lower limit. Conversely, when a natural value reaches a minimum defined lower limit, the value wraps around to the upper limit. The purpose of natural types is for use in hash tables, queues, indexes, compass bearings, time calculations, trigonometric functions, and so forth. The definition of the predefined uint type is shown here.
type natural is integer range natural`first to natural`last;
where: natural`first = 0
natural`last = 18,446,744,073,709,551,615
A good example of the use of natural types would be in computing compass bearings. Most compasses use a system of degrees that range from 0 degrees (North) to 359 degrees. It is useful that when a calculation reaches a heading of 359 degrees that it wrap back around to 0 degrees. Similarly, when a clock reaches 24 hours, it should wrap back around to 0 hours and start over. Examples of natural type declarations and elaboration are shown here.
Figure 35. Natural Declaration and Elaboration type time_val is natural range 0 .. 24; -- Constrained natural type declaration var x : time_val = 10; -- Initialized variable object var y : time_val; -- Uninitialized variable object var z : time_val = 26; -- Valid assignment var z : time_val = -5; -- Invalid; cannot assigned a value < 0
Unsigned integer values have a second unique property in that they cannot underflow or overflow their defined minimum and maximum values. However, any values that exceed user-defined range specifiers will cause program execution to halt and a bounds error to be reported.
Finally, any attempt to divide by zero will cause program execution to halt and a divide by zero error message to be reported. However, the divide_by_zero pragma can be set so that instead of halting program execution, the compiler returns a zero in the case of a divide by zero condition. The purpose of the divide_by_zero pragma is to keep the program from halting during critical operations.
Updating Gehani p21, Ada2012 p189.
Reference types represent objects that reference locations in memory. Locating a value stored at the referenced location is known as dereferencing the object. Mainstream programming languages implement what are called pointers that point to (make reference to) values stored in memory. Using pointers sometimes improves program performance and allows operations that otherwise would be very difficult to perform. Unlike Ada, Ada/PM uses the term pointer to refer to safe reference types. Like Ada, the term pointer is meant to mean that the language allows access under controlled circumstances to memory locations.
A ref type is a variable whose value is the address of another variable in memory. Like any variable or constant, ref types must be declared before they can be used. All ref types are set to null if not explicitly initialized. Ref types may be named or anonymous. The syntax for named ref type declarations looks like this:
type identifier is ref type -- Named pointer type
As an example, to point to a string variable, the following type declaration would be used:
type Summary is ref string;
The previous example declares a ref type named Summary that can only point to string variables. The declaration is read as: "type Summary is a reference to a string type." No object has been created yet, only a template. To point to a variable in memory, a ref object (variable) must be declared like this:
type Summary is ref string; -- Declare a named type template var ptr_str : Summary; -- Declare a pointer object in memory
Keep in mind that the ref object ptr_str in the previous example can point only to string objects stored in memory. Note that it is not explicitly instantiated (i.e., does not point to an actual string variable). Therefore, the compiler implicitly sets ptr_str to null. To point to a string variable, the ref object must be assigned the address of the variable to point to. This is done using the address of operator as depicted in this example:
var str : string = "Hello, world!"; ptr_str = &str -- ptr_str now contains the address of str
In this example, a string variable named "str" is declared and initialized. Notice that when the variable's address is assigned to a ref object, the pointed to variable is taken out of scope because it loses ownership of its memory location. The ref variable is then given ownership of the memory location thus preventing a situation called aliasing whereby more than one variable simultaneously points to the same location in memory.
Preventing more than one variable from pointing to the same location in memory at the same time is a built-in safety feature of Ada/PM. When the ref variable is freed up, ownership of the memory location transfers back to the original variable.
Another safety feature of Ada/PM pointers is that if a ref variable points to a string variable, the access variable is limited to accessing only the number of characters reserved for the string variable. This is designed to prevent malicious code from taking advantage of pointers by accessing data beyond the allocated string size.
Anonymous ref types may be declared using the syntax shown in this example:
var identifier : ref type [= initializer];
Here is an example showing how to use anonymous pointers:
var str : string = "Hello, world!"; str_ptr : ref string = &str; -- str_ptr is assigned the address of str
In this example, the str_ptr declaration is read as: "str_ptr is a ref variable that points to a string type (of 255 characters) and contains the address of str." Remember that the address of operator & yields the address of the named object, in this case the variable str. Here are some more examples of anonymous pointer types in action:
Figure 36. Anonymous Access Types var ret : aliased integer = 15; -- Make sure ret is not placed in a register var int_ptr : ref integer = addr(ret); -- Assign address of ret to int_ptr int_ptr.all = 100; -- Assign 100 to the variable ret ^int_ptr = 100; -- Alternate form of dereferencing a ref type int_ptr = addr(ret); -- Assign the address of ret to itself int_ptr = null; -- Relinquish ownership of ret
Numeric literals also can be written in base 2 (binary), base 8 (octal), and base 16 (hexadecimal). Numbers using a base other than 10 must begin with a zero. Following the zero, binary numbers are represented using the "b" infix symbol, octal numbers use the "o" infix symbol while hexadecimal numbers use the "x" infix symbol. Underscores can be interspersed within adjacent digits to make reading easier. Number representations A through F can be in upper or lower case. Here are some examples of base representations:
0b10111001 -- Base 2 (binary) representation 0o15.0 -- Base 8 (octal) representation 0xFF23_A3B4 -- Base 16 (hexadecimal) representation 0xff23_a3b4 -- Same as previous representation 0x8000000000000000 -- Integer`first in hexadecimal 0x7fffffffffffffff -- Integer`last in hexadecimal 0b10000000_00000000_00000000_00000000_00000000_00000000_00000000_00000000 -- Integer`first in binary 0b01111111_11111111_11111111_11111111_11111111_11111111_11111111_11111111 -- Integer`last in binary
In some cases, we need a variable only temporarily. For example, consider the following situation:
with io;
package Test is
function Sum(x, y: integer) return integer is
var total: integer;
begin
total = x + y;
return total;
end Sum;
begin
io.put (Sum (15, 100));
end Test;
In the Sum() function, note that the total variable is only used as a temporary placeholder variable. It doesn’t contribute much. Its only function is to transfer the result of the expression to the return value.
There is an easier way to write the Sum() function using an anonymous variable. An anonymous variable is a variable that has no name (identifier) associated with it. Anonymous variables in Ada/PM have expression scope, meaning they are destroyed at the end of the expression in which they are created. Consequently, they must be used immediately!
Here is the Sum() function rewritten using an anonymous variable:
with io;
package Test is
function Sum(x, y: integer) return integer is
begin
return x + y; -- x + y creates an anonymous literal variable in a register
end Sum;
begin
io.put (Sum (15, 100));
end Test;
When the expression x + y is evaluated, the result is a literal, which is placed in an anonymous variable, usually on the stack or in a register. A copy of the anonymous literal is then returned to the caller by value. This works not only with return values, but also with function parameters. For example, we can write the following:
with io; package Test is begin io.put (15 + 100); -- 15 + 100 resolves to an anonymous literal because it is not named end Test;
In this case, the expression 15 + 100 is evaluated to produce the result 115, which is placed on the stack or in a register. The value of the anonymous literal is then passed to the io.put() function, which outputs the value 115 to the standard output device. Note how much cleaner this keeps the code. The code is not littered with temporary variables that are only used once.
This feature should not be confused with dynamic typing. While anonymous types allow programmers to define fields seemingly "ad hoc," they are still static entities. Type checking is done at compile time and attempting to access a nonexistent field will cause a compiler error. This gives programmers much of the convenience of a dynamic language, with the type safety of a statically typed language.
Updating Gehani p5, Spark2014 p32.???
Composite data types are variable objects comprised of one or more primary data types grouped together in a single structure. The purpose of composite data types is to provide a method for managing multiple elements of related data using a single structure. Composite data objects are created (instantiated) by means of declarations like other variable objects. Ada/PM has four built-in composite data types: arrays, maps, strings, and records.
Ada/PM array types represent simple data structures that hold multiple homogeneous data elements. Homogeneous means equally sized data elements of the same data type. Elements within an array are accessed using discrete (ordinal) indices. The lower bounds of Ada/PM arrays start at 0 by default. Ada/PM allows multi-dimensional arrays, although one- and two-dimensional arrays are the most common.
Ada/PM provides only constrained arrays. Constrained arrays require explicit static sizes to be assigned. Dynamic, or unconstrained, arrays are not allowed in Ada/PM because they are inherently unsecure and can't be easily validated statically. However, all arrays may be explicitly redimensioned (resized) during program execution. Definitions of the predefined array type are shown here:
type name is array [index] of type; -- Default lower bounds starts at 0 type name is array [index, index] of type; -- Two-dimensional array
The reserved word array declares this composite data structure to be of type array. index defines the number of individual elements that can be assigned to the array. Array lengths and bounds must be ordinal type values. type defines the type of variable elements that will be contained within the array during program execution. Here are some examples of array types:
type small_array is array [1..9] of integer; -- Array of 9 integer elements type buffer is array [1..32767] of char; -- Array of 32,767 char elements type work_hrs is array [1..5] of week_days; -- Array of 5 elements of an enum type week_days
Anonymous array syntax is shown here:
var identifier : array [index] of type;
Figure 37 shows anonymous arrays and how values are assigned to each element.
Figure 37. Anonymous Array Types var a : small_array => 0; -- Goes to symbol (=>) assigns zero to all elements var myArr : array [1..4] of modular; myArr[0] = 0; myArr[1] = 10; myArr[2] = 20; myArr[3] = 30;
In the previous example, "a" is declared as type small_array and every element was initialized to 0 using the goes to symbol =>. The next line in the example declared "myArr" as an array of four elements of type natural. The follow-on lines initialized each element using indexing. Remember, Ada/PM arrays start at index 0.
Array aggregates are used to initialize anonymous array objects and are represented by a collection of elements enclosed in braces. Braces are used so as not to overload other symbols such as brackets and parentheses. Braces also allow aggregate lists to span multiple lines. Here are some examples of array aggregates:
var int_array : array [1..5] of integer = {25, 10, 1, 0, 100}; -- Assign five integers
var flt_array : array [1..3] of float = {0.0, 100.0e15, 125.12345}; -- Assign three floats
Ada/PM strings are predefined homogeneous types representing an array of zero or more characters. A string array of zero characters is defined as the null string. Individual characters within a string are accessed using standard array indices that start at 1. The first byte of all Ada/PM strings contains its length. The default length of string variables is 255 characters because unconstrained strings are not allowed for security and validation reasons. User-defined string types may alter a string's length. Definitions of the predefined string type are shown in Figure 38.
Figure 38. Type String Definitions type identifier is string; -- Constrained string array of 255 characters type identifier is string [1..10]; -- Constrained string array of 10 characters
The reserved word string declares this composite data structure to be of type string. String variables default to a length of 255 characters. All declared string variables are mutable. That is, they may be changed during program execution.
Anonymous strings may be declared too. They evolve from universal type string. The syntax for anonymous string declarations is shown here:
var identifier : string [[range] = "string"];
Example anonymous string declarations and initialization:
var str : string = "Hello, world!"; -- String of length 255 var myStr : string [1..32]; -- Length of 32 including the nil terminator
Conversely, strings declared as const are immutable and placed into read only memory segments with a length equal to the number of characters included between double quotations plus one byte for the nul terminator "\0". Note that string constants must be defined (i.e., given a value) or the compiler will raise an error. The syntax for string constants is shown here:
constant identifier : string = "string";
Here are examples of constant string declarations:
constant prompt : string = "Press any key to continue..."; -- Immutable string of length 28 str : string = "Hello, world!"; -- Immutable string of length 13
When the length of a string is reported, the nil terminator '\0' is not included in the count.
String aggregates are used to initialize string objects and are represented by a sequence of zero or more characters enclosed in quotes " ". Quotes are used so as not to overload other symbols such as braces, brackets, parentheses, or apostrophes. Strings must fit on one line. The plus sign (+) may be used to catenate strings together or placed on multiple lines. Figure 39 shows examples of string aggregates.
Figure 39. String Aggregates var str1: string = "Ada/PM is fun!"; -- String variable with length 255 including '\0' var str2: string [1..20] = "Doe, John"; -- Initialized 20-character string including '\0' var str3: string; -- Uninitialized string with default length of 255 var nullStr: string = ""; -- Null string with length of 255 var emptyStr: string = " "; -- Empty string with length of 255 type new_string is string [1..128]; -- String type declaration with length 128 var s: new_string = "This is a string."; -- Elaboration of s as new_string with length of 128 constant str : string = "Hello, world!"; -- Constant with length of 13 not including '\0'
The null string is often used to check if a string has been initialized. A type string defined with no size specifier or initializing string in quotes defaults to 255 bytes of memory space. Non-constant strings with large size specifiers are designed to be flexible so that the characters in the string may be altered and the size of the string can shrink or grow as necessary within the specified range.
Updating Gehani p18. heterogeneous types.
A record is a collection of fields of the same or different data types, fixed in number and sequence. Each field has a name and a type associated with it. The total storage required for a struct object is the sum of the storage requirements of all the fields, plus any internal padding. Individual fields are accessed using dot notation. Ada/PM implements six kinds of records: basic record, tagged record, variant record, null record, discriminated record, and union.
Syntax for a basic record:
type identifier is
record
identifier : type [range];
identifier : type range lower..upper;
end record;
Example record implementations:
type str_len is string [1..20]; -- Define a type that changes the string length
type Rec is
record
name : str_len;
age : integer;
score : float;
end record;
A record is merely a template. It does not take up any memory space. To instantiate a record, the template must be assigned to an object like this:
var r : Rec; -- r represents an object that is assigned memory space equal to sizeof(Rec)
Dot notation is used to initialize record fields:
r.name = "John Doe"; r.age = 30; r.score = 92.5;
Record aggregates => Spark2014 p55.
Record fields may be assigned using aggregates. This is depicted next:
var r, s, t : Rec; -- Declare three objects of type Rec
r = {"John Doe", 30, 92.5};
s = {"Jane Doe", 22, 88.6};
t = {"Allen Smith", 54, 98.4};
A tagged record is associated with what other languages call a class. Classes require a package containing a set of declared primitive operations. A discussion on tagged records is contained in the section on classes.
A variant record is a composite record object consisting of a component field list. Part of the component field list remains constant while the rest may vary. The variation part of the component field list is based on a discriminant. For example:
type gender_variant is {male, female}; -- Declare a discrimanant type
type Personnel_Record (gender : gender_variant) is -- The gender parameter is the discriminant
record
lname : string [1..32];
fname : string [1..32];
age : modular;
A1C_test : bool;
case gender is
when male then
prostate_exam : bool;
hypertension_test : bool;
cholesteral_test : bool;
when female then
breast_exam : bool;
pregnancy_test : bool;
Dexa_scan : bool;
end case;
end record;
In the previous example, Personnel_Record is the name of the record. The component field list consists of lname, fname, age, A1C_test, and gender. The discriminant, gender, may vary according to individual gender variation. If gender = male, then the variant fields are prostate_exam, hypertension_test, and cholesteral_test. If gender = female, then the variant fields are breast_exam, pregnancy_test, and Dexa_scan. The variant record clearly allows for more flexibility in describing fields that appear structurally similar.
Variant records can become very complex quite rapidly. For the purposes of simplicity, Ada/PM only provides very basic support for variant records. For instance, only one discriminant can be declared. Discriminants cannot be recursive, nor can they be nested. Additionally, discriminant parts are immutable. That is, once a discrimanant field is selected for a record, it cannot be changed. To change the discriminant part of a variant record requires the record to be deleted and then recreated.
Null records are used when a type without data is needed as a placeholder. The way to declare a null record is shown here:
type Some_Record is
record
null;
end record;
Ada/PM programmers often use the null record when the record type is incomplete or ill-defined but need to show how the record will be expanded as programming progresses.
Discriminant records use parametrized variables to affect one or more record field components that depend on the discriminant. For example:
type Buffer_Record (length : integer = 1024) is
record
serial_number : modular;
buffer : string [1..length];
end record;
In the previous example, the discriminant "length" acted as a parameter for the "buffer" field in the record. This example also supplies a default value of 1024. The discriminant parameter in the example can be applied as shown here:
var Buff1 : Buffer_Record (20) = {1505, "This is a string."};
var Buff2 : Buffer_Record (80) = {2400, "Much longer string than the previous string."};
var Buff3 : Buffer_Record;
Buff3.serial_number = 3675;
Buff3.buffer = "This could be a very long comment if required by the editor.";
In the first declaration, Buff1 was allocated 20 bytes of string space for its buffer. In the second declaration, Buff2 was allocated 80 bytes of string space for its buffer. The third declaration did not provide an initialization number for the discriminant part. Therefore, the default size of Buff3.buffer defaults to 1024. This value was implicitly assigned by the compiler.
A union record is a type whose fields can store different type values at different times during program execution. The field of a union record is mapped to the same address within its object no matter the type. The size of a union object is the size of its largest data type. Unions are generally declared with a discriminant parameter like discriminant records. For example:
type storage_type is enum {bool, char, integer, natural, float, decimal, string}
type Union_Record (T : storage_type) is
record
case T is
when bool then
obj : bool;
when char then
obj : char;
when integer then
obj : integer;
when natural then
obj : natural;
when float then
obj : float;
when decimal then
obj : decimal;
when string then
obj : string [1..32];
end case;
end record;
A union can be instantiated as shown in this example:
var rec : Union_Record;
A union is used as shown here:
rec.obj (integer) = 42; rec.obj (float) = 3.14159; rec.obj (string) = "Hello, world!";
The difference between variant records and union records is such that the type is not actually stored inside the record and never checked for correctness. It's just a dummy. However, free unions are unsafe as they do not allow static type checking. Additionally, once the data value is stored, there is no way of ascertaining what type is stored at that memory location. Union records are generally used to interface with C/C++ programs. It is suggested that they not be used in Ada/PM programs.
Updating Spark p120. Where should this topic be in this document?
Page TopTEXT
Updating Gehani p23, Spark p116.
Updating Gehani p24, Spark p119.
Updating Gehani p26, Spark p118. Relational operators, also known as comparison operators, etc.
Page TopTEXT
Updating Gehani p28, Ada95 p121.
Updating Gehani p28, Spark p126.
Updating Gehani p29, Spark p128.
Updating Gehani p29.
Updating Gehani p30, Spark p129.
Updating Gehani p32.
Updating Gehani p33.
Updating Gehani p33, Spark p133.
Updating Gehani p33.
Page TopGehani p51, Ada2012 p161, Spark p33, 134, Spark2014 p27.
Ada/PM contains two kinds of subprograms: procedures and functions. Procedures are statements that perform general actions and therefore their parameter passing rules are more flexible the those for functions. Functions are expressions that generally return a single value.
Ada2012 p171, Spark2014 p28.
A procedure is described in a procedure specification or prototype. The actions performed by a procedure are given within the procedure body. Generally, the procedure body consists of the procedure specification, declaration part, and sequence of statements contained between the reserved words begin and end. The following example depicts the syntax of a procedure.
procedure name (parameters) is -- Specification part local declarations -- Declarative part begin statements -- Body end name;
Subprograms don't need to have any formal parameters. Such procedures have a syntax that looks like the following example.
procedure name is -- No parentheses needed local declarations begin statements end; -- Optional subprogram name is not repeated at the end
A procedure is called from elsewhere by writing its name and supplying a set of actual parameters, each of which corresponds to one of the formal parameters. Actual parameters are the objects that the subprogram uses when it executes.
Updating Ada2012 p161, Spark p144, Spark2014 p31.
In Out In-Out Spark p35, Spark2014 p29.
[EDIT--NEED SOME SOLID EXPLAINING]. In contrast to literals, variables or constants are symbols that can take on one of a class of fixed values, the constant being constrained not to change. Literals are often used to initialize variables, for example, in the following, 1 is an integer literal and the three-letter string in "cat" is a string literal.
Page TopPackages are the basic building blocks of Ada/PM programs. A package is a name space consisting of a collection of declarations including imports, constants, variables, types, procedures, and functions. A package can make its facilities available to other packages, called client (child) packages.
Packages are program units composed of two parts: (1) interface unit and (2) execution unit. The interface unit is a specification file providing the declarations and subprogram prototypes needed for clients to use the package. Interface units are public in nature and are visible to clients. The execution unit is the body of the package containing the implementation details of the objects, procedures, and functions. Package body details are typically hidden from clients. The term package refers to the interface specification and package body collectively.
Notice that interface and package bodies are two physically separate and vitally distinct sections. Together they provide modularity and extensibility. Unlike subprograms, packages do not exist primarily to be executed. Instead, they exist primarily for the facilities they provide to clients. Separate interface files have the name of the package with a ".h" extension. The ".h" extension stands for header file. Package body files have the name of the package with a ".pkg" extension. As an example, an interface for a package called Greetings would be saved as greetings.h. A package body for the package would be saved in a file labeled greetings.pkg. All interface files are stored in the Ada/PM/includes/ directory while package body files are stored in the Ada/PM/library/ directory.
Spark p151.
The interface is the specification section of a package. All declarations in the interface are visible to clients of the package. The following example demonstrates the syntax of an interface package, also called a header file:
with package_name;
interface name is
-- Public section
{declarations} -- One or more declarations
{subprogram prototypes}
-- Private section
private
{declarations} -- One or more declarations
{subprogram prototypes}
end name;
Interfaces contain include files and declarations, which are public by default. All interface files must be saved as unformatted text files with the ".h" extension. Note that Ada/PM interface files are very similar to C/C++/Go standard headers. Interface files are structured to maintain familiarity and structural compatibility with C/C++/Go type languages.
The following Listing shows an example of a specification for an interface package called Add_Numbers:
--------------------------------------------------------- -- Listing - Interface for Package Add_Numbers -- Make declarations visible to clients -- Save as unformatted text file with extension ".h" --------------------------------------------------------- with io; interface Add_Numbers is function Add_Floats (x, y: float) return float; procedure Print_Results (str: string); end Add_Numbers; --------------------------------------------------------
Notice how the interface in the previous listing includes the "io" package. The "io" package, also called a header file, defines a function and a procedure. The Add_Numbers interface is the client of the two include packages text_io and float_io found in the "io.h" file. The declarations in text_io and float_io are now visible to and directly usable by the package Add_Numbers.
Ada/PM programs are written and compiled in a certain context. The context of a program determines what external elements are available to the program for its use. Clients can gain access to declarations in other packages by using the with reserved word. For example, a main program unit cannot use the types, variables, functions, or procedures in another package such as the io package previously shown until the package is implicitly included.
Only one support package may be named on a line. This simplifies compiler development and enhances readability. It is mandatory to name included packages in the package interface. However, Ada/PM rules state that if a package is imported in a named interface, by extension it is also included in the associated named package whether the named package also includes the same interface unit. Ada/PM rules also state that the effect of including a support package more than once is the same as importing it once. Therefore, it is not necessary to repeat the with statement in the package body when it is already included in an interface unit. with clauses use the following syntax to make packages visible to clients:
with package_name -- Files located in the default subdirectory or with c:/documents/user/name.inc -- User location
The compiler will search in the default directory for the interface file. The default directory is Ada/PM/include/name.inc. Alternatively, programmers can include a different directory for the compiler to search by including the full search path. Once interface declarations are imported, they are referenced by prefixing their names with the name of the included package and a period. This is called dot notation or more formally, fully qualified reference. Examples of fully qualified reference conventions are shown here:
with io, math; -- Imported packages
...
io.put ("This is a string."); -- Fully qualified references must be used
io.put (math.sin(12345));
Interfaces must begin with the interface reserved word followed by the name of the interface package. The compiler checks its symbol table to see if the package is already included elsewhere. If not, then it uses interface_name to define the package. If the interface package of the same name is already included, it does not include it again.
The syntax for interfaces and package bodies are shown below:
-- Interface package
with package_name;
interface interface_name is
-- Public part
{declarations}
-- private part
private
{declarations}
end interface_name;
Packages must begin with the reserved word package and end with the reserved word end followed by the package name and semicolon.
-- Package body package name is declarations begin sequence of statements end name;
Example package:
----------------------------------------------------------
-- Interface for Add_Numbers
-- Save as Add_Numbers.h text file
----------------------------------------------------------
with io;
interface Add_Numbers is
function Add_Floats (x, y: float) return float;
procedure Print_Results (str: string, result : float);
end Add_Numbers;
----------------------------------------------------------
-- Package body for Add_Numbers
-- Build as object file
----------------------------------------------------------
package Add_Numbers is
var temp : float;
function Add_Floats (x, y: float) return float is
begin
temp = x + y;
return temp;
end Add_Floats;
procedure Print_Results (str: string, result: float) is
begin
io.put (str, result);
io.new_line;
end Print_Results;
begin
temp = 45.0; -- Set temp to a default value
end Add_Numbers;
----------------------------------------------------------
-- Main program
-- Build as executable
----------------------------------------------------------
with Add_Numbers, io; -- with io is ignored by the
-- compiler because its already
-- included in Add_Numbers.
package Do_Something is
var temp: float;
begin
tempflt = Add_Floats (15.5, 100.25);
Print_Result ("The result is: ", tempflt);
end Do_Something;
The program outputs:
The result is: 150.75Page Top
Janus/Ada User Manual, p8-1.
Page TopJanus/Ada User Manual, p9-1.
Page TopJanus/Ada User Manual, p10-1.
Page TopAda/PM does not implement classic object-oriented programming (OOP). Instead, it utilizes built-in constructs to add object-based functionality. Ada/PM classes are just templates that describe the details of objects from which individual objects are created. Ada/PM classes are composed of three items: a name, properties (variables), and methods (procedures and functions). A class declaration does not take up any memory space.
In programming terms, an object is a self-contained structure that contains properties and methods needed to make a certain type of data useful. An object's properties are what it knows, and its methods are what it can do.
When declaring classes, Ada/PM adds two descriptors to every class type: name of the current type, and the size in bytes needed to store the object. The name of the current class serves as a reference to the first member of its structure. Further, classes are designed so that users cannot short-circuit the methods associated with a class.
In object-based programming, a class is a construct that defines a collection of related properties and methods. A class is just a structure encapsulated in a container called a class. Classes represent templates that act as blueprints for objects. Objects are instances of classes. They share the common structure that the class defines and occupies memory space.
In Ada/PM, classes have members that represent their data and behavior. Members of an Ada/PM class are either methods (procedures or functions) or properties (variables). Therefore, properties defined in a class are called member properties. The term properties is used to mean class variables.
The term method is used to distinguish non-object-based functions from object-based functions, which are associated with objects. When the term method is used, just know that we are discussing class-related procedures and functions. Methods are used to control or report the state of an object in a class.
Encapsulation (information hiding) is the inclusion within a container of all the resources needed for an object to function; basically, its data and methods. Ada/PM uses the reserved word class as the containing structure. The whole business of encapsulation is to hide how classes do their jobs. This feature prevents users from altering or subverting the functionality of class objects.
This example demonstrates how to set up an encapsulated class template:
with io;
class Shape is
type Rectangle is private
record
-- Class properties (attributes)
width : float;
height : float;
name : string [16]; -- Added by compiler
size : integer; -- Added by compiler
end record;
-- Class methods (behaviors)
procedure Set_Area (this : Rectangle; x, y : float) is
this.width = x;
this.height = y;
end Set_Area;
function Get_Area (this : Rectangle) return float is
return (this.width * this.height);
end Get_Area;
procedure Put_Area (this : Rectangle) is
io.put ("Area = ", this.width * this.height);
end Put_Area;
function Get_Size (this : Rectangle) return integer is
return (this.size);
end Get_Size;
end Shape;
As mentioned, a class is just a template that takes up no memory space. To create space in memory for the class, an instance of the class must be declared. An instance is a specific object built from a specific class. It is assigned to a reference variable that is used to access all the instance's properties and methods. When you make a new instance, the process is called instantiation and is typically done using the new reserved word. Here is an example of how to instantiate an object of class Shape:
R : Rectangle = new Rectangle(); -- Create space on the heap and return a pointer Set_Area(R, 10.5, 20.25); n = Get_Area(R); -- n = 212.625 Put_Area(R); -- Output 212.625 n = Get_Size (R); -- n = 40
Notice that the only way to call a method is to pass the object name itself as the first argument. Consequently, the first parameter to every method must be of a type that contains the object. The remaining arguments must be addressed by the method declaration in the object.
The private reserved word makes data and methods in a class private. This is referred to as data hiding. Private data and methods can be accessed only from inside the class itself. If data and methods are not designated as private, then they are public by default. Public data and methods can be accessed outside of the class. If you try to access private data from outside of the class, the compiler will raise an error.
Note the reserved word new in the previous example. New is an allocator, which is followed by the construct to be allocated. The result of an allocation is a pointer to a location in heap memory where the object will be stored. The process of declaring an object and creating space on the heap is called instantiation. After instantiation, the Rectangle object now has an internal table at storage location Rectangle where the table contains the following fields:
Rectangle:
.name "Rectangle" -- 16 bytes
.width 0.0 -- 8 bytes
.height 0.0 -- 8 bytes
.size 40 -- 8 bytes
The term inheritance refers to the ability to incrementally build new types from existing ones by keeping, modifying, and adding properties. Since Ada/PM is not designed to be a fully functioning OOP language, it does not support inheritance.
The term polymorphism as it relates to object-based programming means the ability to request that the same operations be performed on a wide range of different object types. Ada/PM uses two different techniques to implement polymorphic characteristics: method overloading and operator overloading.
Method overloading is an ad-hoc, static form of polymorphism. That is, one operation name stands for many different, but not necessarily related, subroutine implementations. Although they all have the same names, their profiles are different. When an overloaded operation is called, the correct subroutine implementation is chosen at compile-time, i.e. overloading is resolved by static binding of an implementation to an operation call.
Although the method name may stay the same, the parameters, the return type, and the number of parameters can all change. Here is an example of method overloading:
class Shape is
type element is private;
type Rectangle is
record
name : string [16];
length : element;
width : element;
size : integer;
end record;
function Set_Area (this : Rectangle; x, y : element) return null is
begin
this.length = x;
this.width = y;
end Set_Area;
end Shape;
class Shape is
type element_type is {integer, natural, float, decimal};
type Rectangle (T : element_type) is
record
name : string [16];
case T is
when integer then
length, width : integer;
when natural then
length, width : natural;
when decimal then
length, width : decimal;
else
length, width : float;
end case;
size : integer;
end record;
function Set_Area (this : Rectangle; x, y : T) return null is
begin
this.length = x;
this.width = y;
end Set_Area;
end Shape;
Operator overloading allows some or all of operators like +, -, or != to be treated as polymorphic functions and as such have different behaviors depending on the types of its arguments. For instance, the plus sign + can be used to add integers, floating-point numbers, or to combine two strings. The minus sign can be a unary operator like in -15, or a minus sign like in 15 - 10.
Page TopJanus/Ada User Manual, p12-1.
Page TopJanus/Ada User Manual, p13-1.
Page TopThis chapter describes the full complement of Ada/PM input-output (I/O) facilities contained in the io and file_io libraries.
Janus/Ada User Manual Ch 14
Ada/PM I/O centers around the concept of data streams for file and devices I/O. Streams can be either binary streams or text streams. A stream represents a channel by which data can flow from the execution environment to the programs and vice versa. Files can reside on CD-ROMs, USB devices, or in memory and can be output to consoles, printers, and various storage devices. All I/O is performed in the same manner, no matter what file or device the I/O is utilizing. Binary streams are associated with binary-mode files while text streams are associated with text-mode files consisting of a sequence of lines. Each line contains zero or more characters and ends with one or more symbols that mark the end of the line. Text-mode lines are not terminated with a null (/0) character as are strings.
File I/O to disk devices is performed through library routines using Window's New Technology File System (NTFS) format. The syntax of a Window's file is:
[d:][path]file_name[.ext]
where "d:" is an optional disk name, "path" is an optional path consisting of directory names followed by a backslash (\\) escape sequence, "file_name" is the name given to a file, and ".ext" is the optional extension appended to the file name. Technically, Windows file names are limited to 260 characters including the path, file_name, and extension. The next Figure is an example file-naming convention.
with file_io; package Test is var file_name : string; begin file_name = "c:\\directory\\file.txt"; end Test;
A file represents a sequence of bytes. Before any file I/O can be done, the file object must be bound to an external file. This is called opening a file. The open() function associates a file with a stream and initializes an object of type FILE. The open() file function returns a pointer to a FILE object for the stream associated with the file being opened. Once a file is opened, functions that transfer data can be called to manipulate the stream. Each data transfer function has a pointer to a FILE object as one of its arguments. The FILE pointer specifies the stream on which the operation is used.
Whenever open() is used in a program, a check for errors should always be done. If an error occurs while attempting to open a file, the open() function returns the NULL value. Typical errors are raised when:
Similarly, to string arrays each character in a file stream has a specific position in the file. The first character is at position zero (0). Ada/PM uses a file position indicator as part of the object representing a stream to indicate the position of the next character to be read or written. When a file is opened in append mode, the file position indicator generally points to the end of the file. Every read or write operation advances the indicator by the number of characters read or written.
In console mode, file streams are typically stored in a buffer to increase read-write efficiency. Ada/PM streams can be buffered in one of three ways: fully buffered, line-buffered, and unbuffered. Characters stored in fully buffered environments are normally transferred (flushed) only when the buffer is full. Characters in line-buffered environments are normally transferred when a newline character is written to the buffer, or when the buffer is full. Sometimes, buffering is not desired, such as when an error is raised. In this case, characters are transferred immediately without being buffered. As shown in the next Figure, the buffer can be flushed using the flush() function.
with file_io;
package Test is
begin
flush ("file_name");
end Test;
Note that buffers are automatically created by the program when it is executed. When a file stream is closed or the program terminates, Ada/PM automatically flushes any open buffers.
The Ada/PM console mode has four standard text streams. These streams do not have to be explicitly opened as the compiler does this automatically when in console only mode. The following Figure lists them by the names of their respective FILE pointers.
FILE Pointer Common Name Buffering Mode Mode stdin Standard input Line-buffered Read only stdout Standard output Line-buffered Write only stderr Standard error output Unbuffered Write only stdlst Printer device Line-buffered Write only
The stdin FILE pointer is generally associated with the keyboard, stdout and stderr with the console display, and stdlst with the default printing device. Of course, these standard text streams can be redirected, for instance, to FAX or modem devices, by closing and reopening to point to a different device.
The IO library contains functions that operate on file systems. These functions take the name of a file as one of its parameters. The following IO library functions do not require the file to be opened:
with file_io;
package Test is
begin
rename ("[d:][path]old_name", "[d:][path]new_name");
delete ("[d:][path]file_name");
create ("[d:][path]file_name");
end Test;
The access mode specifies what input and output operations are permitted by the data stream. The access mode is passed as a second parameter to the open() function and is enclosed in double quotes. Permissible values of the mode string is "r" for "read" mode, "w" for "write" mode, and "a" for "append" mode. Files can be opened in both "read" and "write" mode using the "rw" string. If a file is to be opened in binary I/O mode, then the string character "b" is used. The "b" causes the file to be opened in binary mode; its absence opens the file in text mode.
If the mode string begins with "r", then the file must already exist in the system. If the mode string begins with "w", then the file will be created if it does not already exist. If it does exist in the system, then its previous contents will be discarded because the open() function truncates the file to zero length in "w" mode. The permitted values for mode are listed in the following Figure.
Mode Description
r Opens a file for reading only. If the file doesn't exist, a NULL is returned.
w Opens a file for writing only. If the file doesn't exist, it is created. If the file
exists, the file is deleted and a new one is created.
a Opens a file for appending. If the file doesn't exist, it is created. If the file
exists, data are appended starting at the end of the file.
r+ Opens a file for reading and writing. If the file doesn't exist, it is created. If
the file exists, new data are added starting at the beginning of the file, overwriting
existing data.
w+ Opens a file for reading and writing. If the file doesn't exist, it is created. If the
file exists, it is overwritten.
a+ Opens a file for reading and appending. If the file doesn't exist, it is created. If
the file exists, new data are appended starting at the end of the file.
b Opens a file in binary mode. The "b" is appended to any of the previous modes.
The prototype is: fp : FILE = function open("file_name", "mode" is) return integer. An example is shown in the Figure below.
with file_io;
package Test is
var fp : FILE;
begin
fp = open ("c:\\programs\\file_name", "rw"); -- Open a text file to read and write mode
if fp = 0 then then perror ("Last error"); -- Check for error while opening the file
end Test;
To close a file, use the close() function. The file pointer for the file to be closed is passed as a parameter to the function. The prototype is: function close(fp : FILE) return Boolean;. The close() function returns a Boolean value indicating success (1) or failure (0). An example is shown in the next Figure.
with file_io;
package Test is
var fp : FILE;
var result : bool;
begin
fp = open("c:\\programs\\file_name");
result = close (fp);
if result = 0 then perror ("Last error"); -- Check if error occurred while closing the file
end Test;
Ada/PM file functions are secure in that they provide exclusive access where supported by the operating system.
See C in a Nutshell, p214 C11 fopen_s(), etc.
Currently, Ada/PM only supports the UTF-8 one-byte character standard. Wide characters, e.g., two-byte and four-byte sized character sets are not implemented by the compiler. Multi-byte character sets are planned in future releases.
Binary (direct) I/O refers to input-output done in machine readable format. Generally, this method of I/O is faster than text (serial) I/O. Data is accessed randomly without having to read a file sequentially from the beginning. All direct I/O functions are in the IO library.
Binary I/O consists of a stream of bytes that are transmitted without modification. That is, direct I/O functions do not provide any interpretation of control characters when operating on binary streams. Binary streams are typically used for database records. Note that Ada/PM only implements binary I/O for primary and composite types. Attempted binary I/O of non-primary or non-composite types will raise an error.
WARNING saving access type values as binary I/O gives meaningless and potentially dangerous results. As access variable values change with each program execution and system, they should not be transferred to files.
Ada/PM binary (random) file access allows users to read or modify data directly at any given position in a file. This is done by setting the file position indicator.
NEED TO DISCUSS SEEK() AND REWIND()/RESET(). See C in a Nutshell, p.236.
with file_io;
package Set_File_Position is
begin
seek ("file_name", sizeof(record), SEEK_CUR); -- Move to next file position
rewind ("file_name"); -- Reset position to beginning of file
end Set_File_Position;
Text I/O stores data in human readable format. Since each line, page, or section of data may be a different size, data must be accessed sequentially. All sequential I/O functions are in the IO library.
Text I/O consists of a stream of bytes that are divided into lines. A line of text is a sequence of characters ending with an end of line (EOL) character (ASCII 26). Ada/PM defines the EOL as \n (new line), with or without an additional \r (carriage return). The \f (form feed) symbol is used as the page terminator.
Ada/PM uses a special terminator character to indicate the end of file (EOF). Generally, the end of file is represented by a ^Z symbol.
If a file consists of the null character (""), the ^Z character is ignored on input. The \r is always ignored on input. They will not be returned by the Get() function for instance. All other control characters are sent directly to the system or device.
When something goes awry during I/O operations, Ada/PM raises appropriate errors. When errors occur, they can be raised in several ways including return values from subroutines, error codes displayed on the standard output device, and the global error variable errno. The functions in the I/O library generally indicate any file-related errors that occur during program execution by their return value. Additionally, they also set an error flag in the
The following is a list of exceptions:
Possible errors:
See Ada/PM stderr library. Several standard library functions support specific file handling errors by setting the global error variable errno to a value that indicates the kind of error that has been raised.
The perror() function outputs its string argument followed by a colon, the error message, and a newline character. The error message is the same as the string that strerror() would return if called with the given value of errno as its argument. The Figure below depicts an example of errno and perror use.
with io, file_io, errno;
package Get_Error is
begin
file.open ("file_name", "r"); -- Assume file doesn't exist
io.put (errno); -- Outputs the error number
errno.perror ("Last error"); -- Outputs a descriptive message of the last recorded error
end Get_Error;
The read() procedure is used to transfer a block of binary data from disk devices such as hard drives, floppies, USBs, and CD-ROMs/DVDs to memory. The write() procedure is used to transfer a block of binary data from memory to a disk device. The types which can be input and output by these two procedures are the string type and all scalar types. All read and write routines pass the data and file name as parameters to their respective functions. Read and Write operations are depicted in the next Figure.
The prototype for the read procedure is: procedure read(buf : pointer; size : integer; count : integer; fp : FILE;). The buffer argument is a pointer to the region of memory holding the data to be written to the file, size specifies the size in bytes, of the individual data items, and count specifies the number of items to be written. For instance, to transfer a 50-element integer array, size would be 4 because integers are 4 bytes in length, and count would be 50 because the array size is 50 elements. The next Figure demonstrates how to read data from a file.
with io, file_io;
package Test is
var fp : FILE;
var buffer : array [1..50] of integer;
begin
fp = open("c:\\programs\\file_name", "rb");
if fp = 0 then perror ("Last error"); -- Check for errors in opening file
read (buffer, 4, 50, fp); -- Read 50-element array into buffer
result = close (fp); -- Check for errors in closing file
if result = 0 then perror ("Last error");
end Test;
The prototype for the write procedure is: procedure write(buf : pointer; size : integer; count : integer; fp : FILE;). The buffer argument is a pointer to the region of memory holding the data to be written to the file. Size, count, and file pointer (fp) remain the same as for the read procedure. The following Figure demonstrates how to read data from a file.
with file_io;
package Test is
var fp : FILE;
var arr : array [10] of integer = {10, 20, 30, 40, 50, 60, 70, 80, 90, 100};
begin
fp = open("c:\\programs\\file_name", "rb");
if fp = 0 then perror ("Last error"); -- Check for errors in opening file
write (arr, 4, 10, fp); -- Write a 10-element array into buffer
result = close (fp); -- Check for errors in closing file
if result = 0 then perror ("Last error");
end Test;
The get() and put() procedures are used to do I/O to standard devices such as the keyboard and console screen. The types which can be input and output by these two procedures are the string type and all scalar types.
DISCUSS OUTPUTTING TO PRINTERS.
Support for low level I/O is accomplished using assembly mnemonics directly in the source code.
Page Top[Ada2012 p385].
Ada/PM's verification tools add contract type interfaces in the form of annotated comments. Annotations employ aspect clauses designed to support abstraction and static source code analysis. When fully implemented, Ada/PM tools will supersede the debugger as the primary provision for validating and verifying source code against the Ada/PM language standard. Annotated comments are denoted using the global, pre, and post keywords. When the verification and validation tool, called Inspector, is executed, it recognizes annotations as contract type instructions.
Spark2014 p76 => Introduction to Contracts.
Ada2012 p385.
Spark p138, OWN Spark p161.
Ada2012 p388.
The following code snippet shows how annotated comments are used in an Ada/PM program.
1. ----------------------------------------------------------------------------- 2. -- Listing - Ada/PM Annotated Comment Syntax 3. -- Calculates total by adding tax to price 4. ----------------------------------------------------------------------------- 5. interface Total_Cost is -- Specification for the package 6. global total: float; -- Make package variables visible 7. 8. procedure Compute_Cost (price: in float) is 9. global out total; -- total is write only 10. pre in price > 0.0; -- Pre-condition check 11. post out total > 0.0; -- Post-condition check 12. end interface; 13. 14. package Total_Cost is 15. var total: float; 16. 17. procedure Compute_Cost (price: in float) is 18. var tax: float; 18. begin 20. tax = price * 0.05; -- Compute tax 21. total = price + tax; -- Compute total 22. end procedure; 23. end Total_Cost; 24. ------------------------------------------------------------------------------
The previous Listing demonstrates how annotated comments are employed in an Ada/PM program. Notice that annotations are applied in the interface and not in the package. However, related refinement annotations may be placed in corresponding packages as necessary. Use of the GLOBAL clause means that the listed objects are in the package. The PRE clause is a pre-condition that explicitly tells Inspector to check that input prices are greater than 0.0. The POST clause is a post-condition that explicitly tells Inspector to check that the final value of total is greater than 0.0.
Page TopCopyright © PMzone Software. All rights reserved. Terms of Use